Amazon Managed Streaming for Apache Kafka
In this post, we will take a look at Amazon MSK — Managed Streaming for Apache Kafka. We will also be looking at a demo for setting up and using Amazon MSK.
Introduction
Managing Apache Kafka on our own can be tiresome and involves dedicated developers with proper skills related to Apache Kafka to maintain the Apache Kafka infrastructure.
Amazon MSK is a fully managed, highly available, and secure service for Apache Kafka. Amazon MSK or Amazon Managed Streaming for Kafka is a fully managed service that makes it easy for us to build and run applications that use Apache Kafka to process streaming data. With a few clicks in the AWS console, we can create highly available Apache Kafka clusters with settings and configuration based on Kafka’s deployment best practices.
Amazon MSK allows us to build and run production applications on Apache Kafka without needing Kafka infrastructure management expertise or having to deal with the complex overheads associated with running Apache Kafka on our own.
Challenges in Using Self Managed Apache Kafka Which Amazon MSK Solves
- Difficult to set up
It can be difficult for many customers to set up especially if they’re not accustomed to running their own distributed infrastructure. It is pretty easy and quick if we are just running a POC and we just want to get a Kafka cluster up and running and we have producers and consumers that are reading and writing from Kafka but the real challenge is setting it up for production.
2. Tricky to scale
It’s also tricky to scale if we add brokers to Apache Kafka because then we have to orchestrate some partition reassignment. Those partitions that the producers are writing and reading from actually have to be migrated to the brokers after we have added a broker to a cluster. Thus we could see performance degradation when the cluster is scaling.
3. Hard to achieve high availability
- For the scale of production, we need to continuously monitor our brokers within Kafka to make sure that if a broker fails we’re maintaining high availability by replacing those brokers.
- The same goes for the Apache zookeeper nodes that too need monitoring and when any node fails we need to replace those nodes too.
- If there are patches that need to be applied or we may also want to upgrade our Kafka installation on our brokers and zookeeper nodes to support the latest and greatest changes. This will require development and automation to set up. All of this also requires keeping an eye for those edge cases that can create unavailability within our cluster. So all of this requires a lot of time, a lot of automation, and a lot of development effort for our teams just to get a cluster in production State up and running.
4. No console, No visible metrics
Apache Kafka doesn’t provide a console out of the box and it doesn’t provide metrics that are also in that console so that we can understand if the cluster is healthy or if our producers and consumers are writing and reading data to and from topics as we intend them to be.
5. A specialized pool of resources to maintain Kafka
Customers’ usage of Kafka is always a function of the amount of site reliability engineering talent that they have on-site or have hired. Otherwise, if they don’t have those engineers they need to ramp up existing engineers with the skill of operating, maintaining, and keeping Kafka highly available. A lot of times those engineers are software developers that would otherwise be allocated towards building applications that are closer to their businesses.
Features of Amazon MSK
- Fully compatible for Apache Kafka 1.1.1, 2.2.1, 2.3.1, 2.4.1
- 99.9% availability SLA
- Encryption in-transit via TLS between clients and brokers, and between brokers
- AWS Management Console and AWS API for provisioning
- Clusters are set up Automatically
- Functionality to provision Apache Kafka brokers and storage
- Create and tear down clusters on demand
- Cluster lifecycle is fully automated
- Brokers and Apache Zookeeper nodes auto-heal
- IPs remain intact
- Patches are applied automatically without downtime
- Apache Zookeeper is under the hood, highly available, and is included with each cluster at no additional cost.
- Data transfer within the MSK cluster is included at no additional charge.
- Amazon Virtual Private Cloud (Amazon VPC) for network isolation.
- AWS Key Management Service (AWS KMS) for at rest encryption.
- AWS Identity and Access Management for control-plane API control.
- Amazon Cloudwatch for Apache Kafka broker, topic, and Zookeeper metrics.
- Amazon Elastic Compute Cloud (Amazon EC2) M5 instances as brokers.
- Amazon EBS GP2 broker storage.
How Amazon MSK Works?
The MSK clusters always run within an Amazon VPC managed by the MSK service. Our MSK resources are made available to our VPC, subnet, and security group through elastic network interfaces (ENIs) which will appear in our account, as described in the following architectural diagram:
Customers can create a cluster in minutes, use AWS Identity and Access Management (IAM) to control cluster actions, authorize clients using TLS private certificate authorities fully managed by AWS Certificate Manager (ACM), encrypt data-in-transit using TLS, and encrypt data at rest using AWS Key Management Service (KMS) encryption keys.
Amazon MSK continuously monitors server health and automatically replaces servers when they fail, automates server patching, and operates highly available ZooKeeper nodes as a part of the service at no additional cost.
Key Kafka performance metrics are published in the console and Amazon CloudWatch. Amazon MSK is fully compatible with Kafka versions 1.1.1 and 2.1.0 so that we can continue to run our applications, use Kafka’s admin tools, and use Kafka compatible tools and frameworks without having to change our code.
How to Setup and Use MSK — A Demo
We can create a cluster using the AWS Management console. We need to give the cluster name, select the VPC we want to use the cluster from, and the Kafka version.
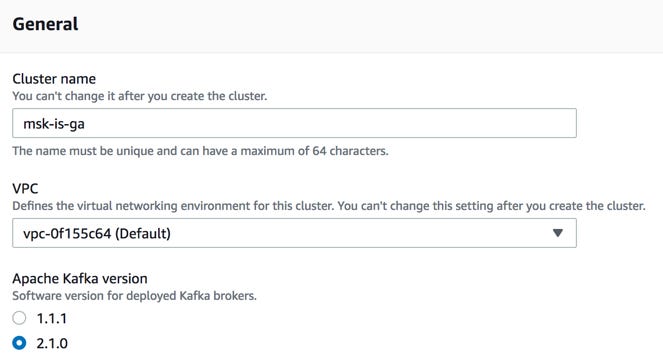
After doing this we choose the Availability Zones (AZs) and the corresponding subnets to use in the VPC. In the next step, we select how many Kafka brokers to deploy in each Availability Zones (AZs). More brokers allow us to scale the throughput of a cluster by allocating to different brokers.

We can add tags to search and filter our resources, apply IAM policies to the Amazon MSK API, and track our costs. For storage, we leave the default storage volume size per broker for demo purposes.

We can select to use encryption within the cluster and to allow both TLS and plaintext traffic between clients and brokers. For data at rest, we will use the AWS managed Customer Master Key (CMK), but we can select CMK in our account, using KMS, to have further control. We can use private TLS certificates to authenticate the identity of the clients that connect to our cluster.
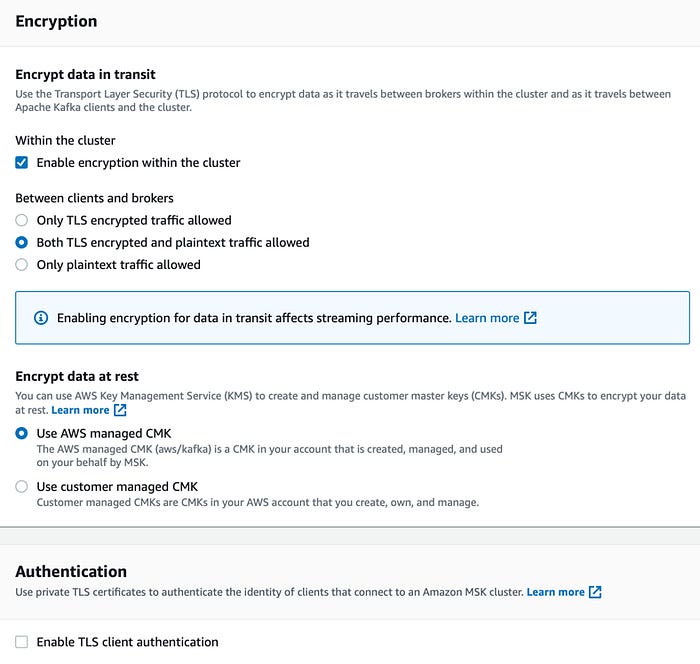
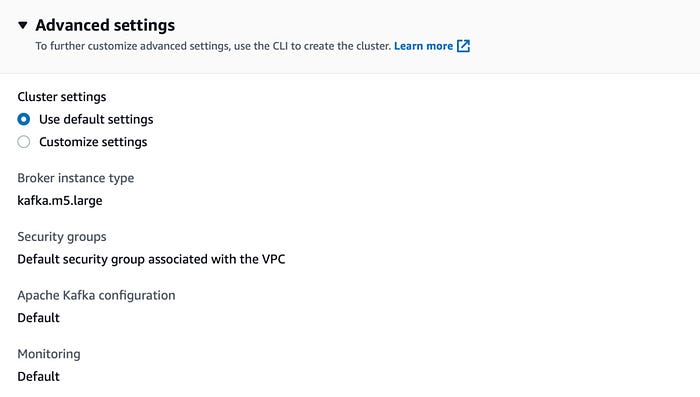
In the advanced settings, we leave the default values for this demo purpose.
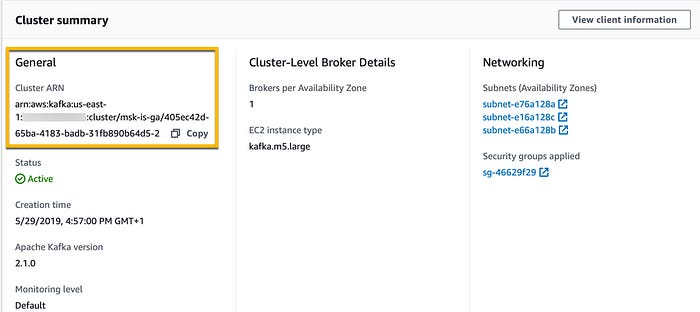
We can create the cluster and monitor the status from the cluster summary, including the Amazon Resource Name (ARN), that we can use when interacting via CLI or SDKs.
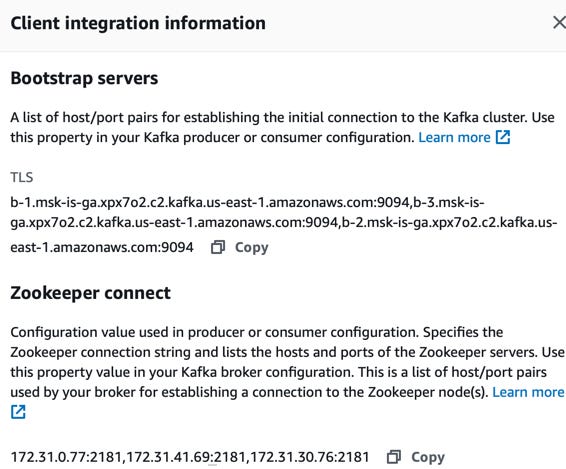
When the status is active, the client information section provides specific details to connect to the cluster, such as :
- The bootstrap servers we can use with Kafka tools to connect to the cluster.
- The Zookeeper connects a list of hosts and ports.
We can get similar information using the AWS CLI:
- aws kafka list-clusters to see the ARNs of your clusters in a specific region
- aws kafka get-bootstrap-brokers — cluster-arn <ClusterArn> to get the Kafka bootstrap servers
- aws kafka describe-cluster — cluster-arn <ClusterArn> to see more details on the cluster, including the Zookeeper connect string.
To start using Kafka, we create two EC2 instances in the same VPC, one will be the producer and one will be the consumer.
To set them up as client machines, we download and extract the Kafka tools from the Apache website.
On the producer instance, in the Kafka directory, we create a topic to send data from the producer to the consumer:
bin/kafka-topics.sh — create — zookeeper <ZookeeperConnectString> \— replication-factor 3 — partitions 1 — topic MyTopic
Then we start a console-based producer.
bin/kafka-console-producer.sh — broker-list <BootstrapBrokerString> \— topic MyTopic
On the consumer instance, in the kafka directory, we start a console based consumer:
bin/kafka-console-consumer.sh — bootstrap-server <BootstrapBrokerString> \ — topic MyTopic — from-beginning
Finally, we send and receive messages.
Conclusion
Amazon MSK or Amazon Managed Streaming for Kafka is a fully managed service that makes it easy for us to build and run applications that use Apache Kafka to process streaming data. Hence the developers do not need to focus on self-managing Apache Kafka which in turn saves the time of developers and results in allowing developers to focus on implementing business logic without worrying about managing Kafka.
